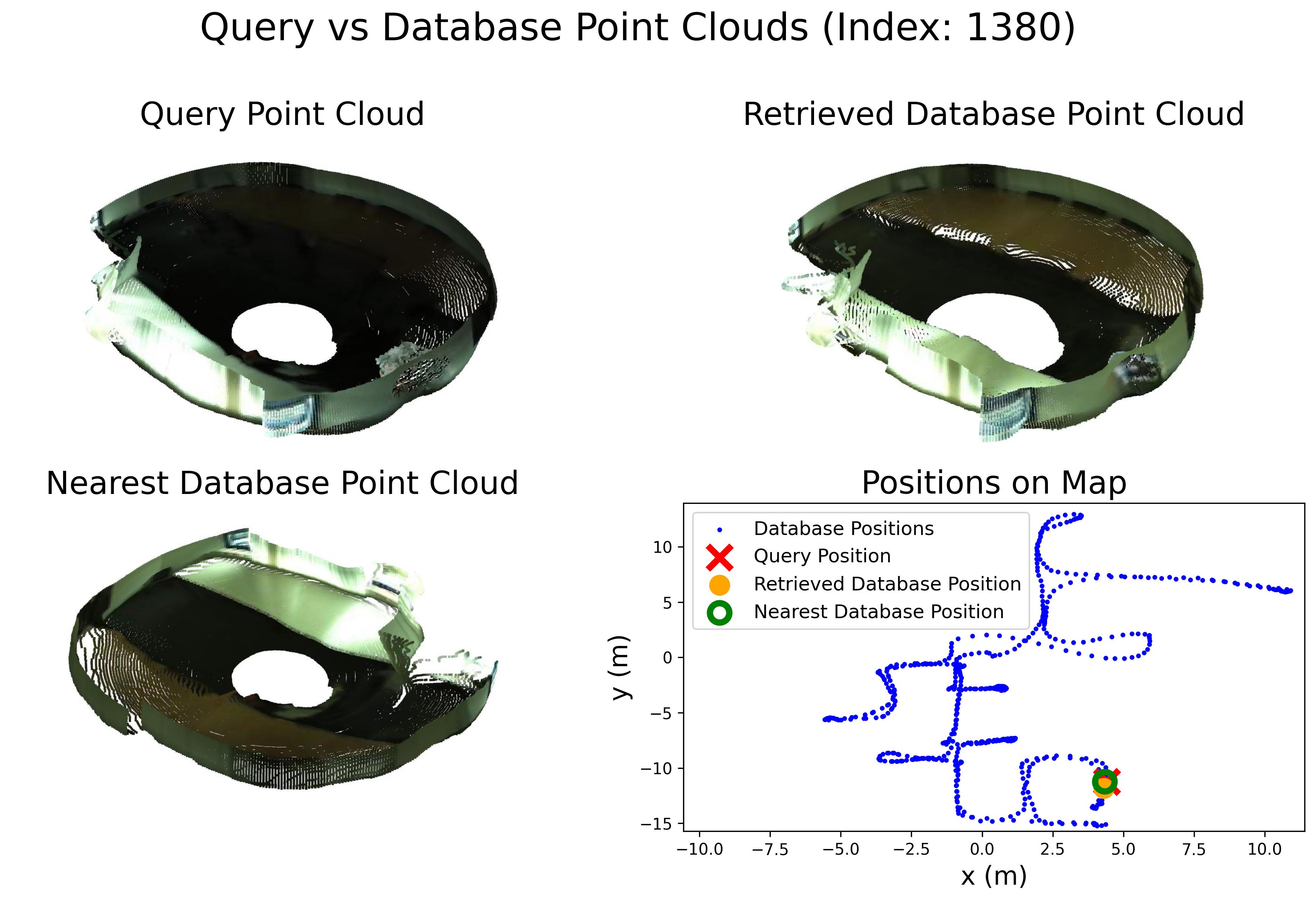
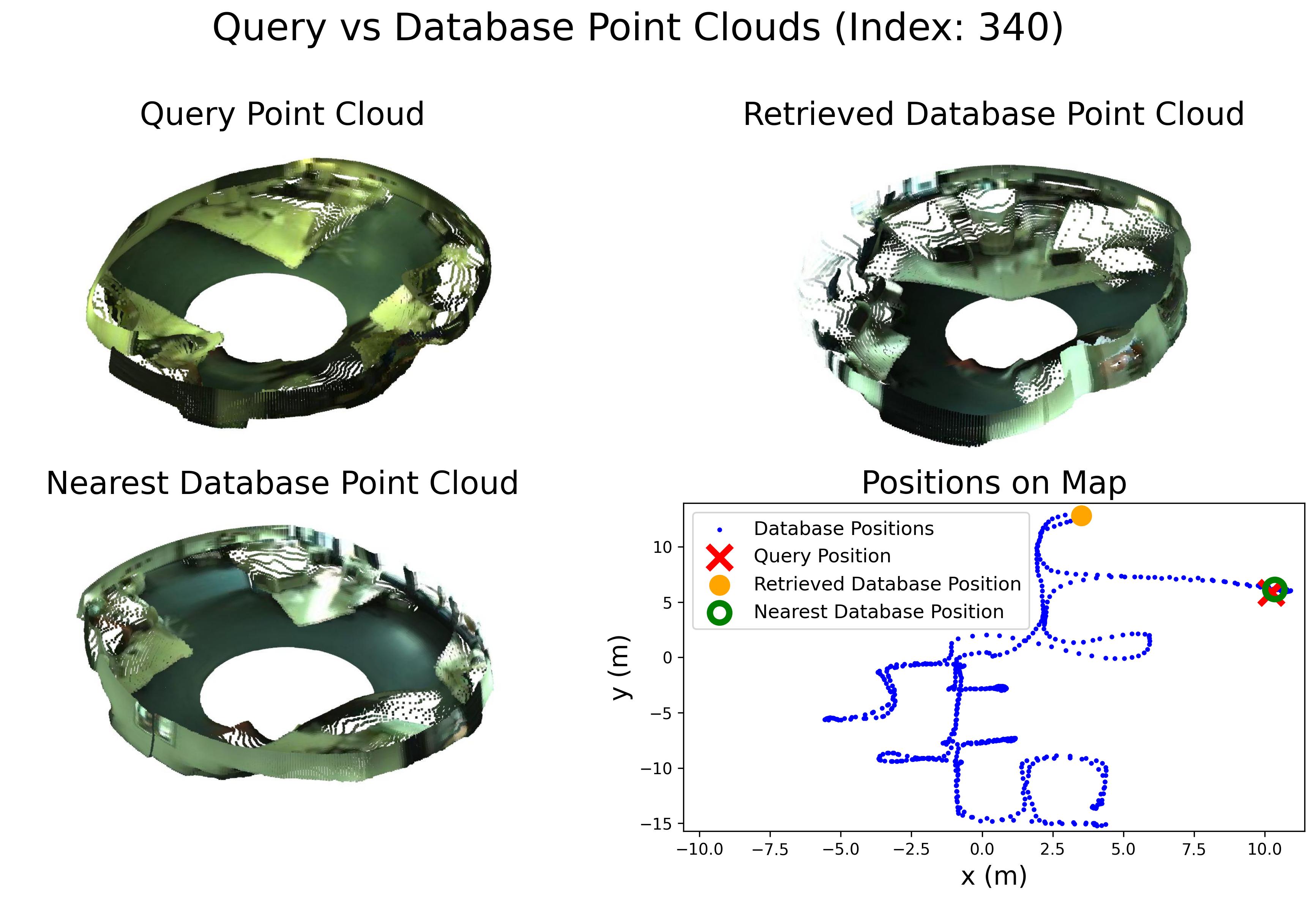
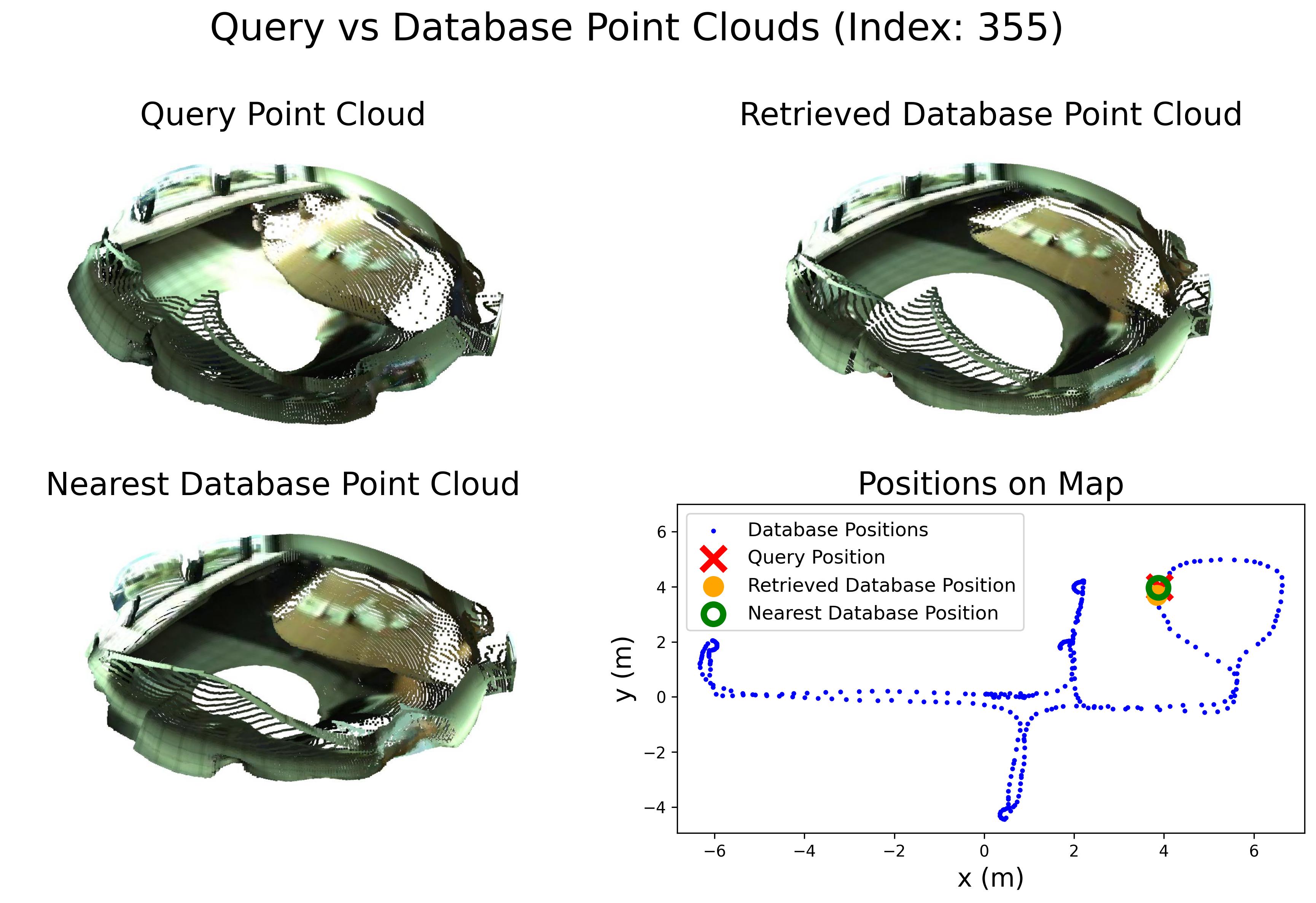
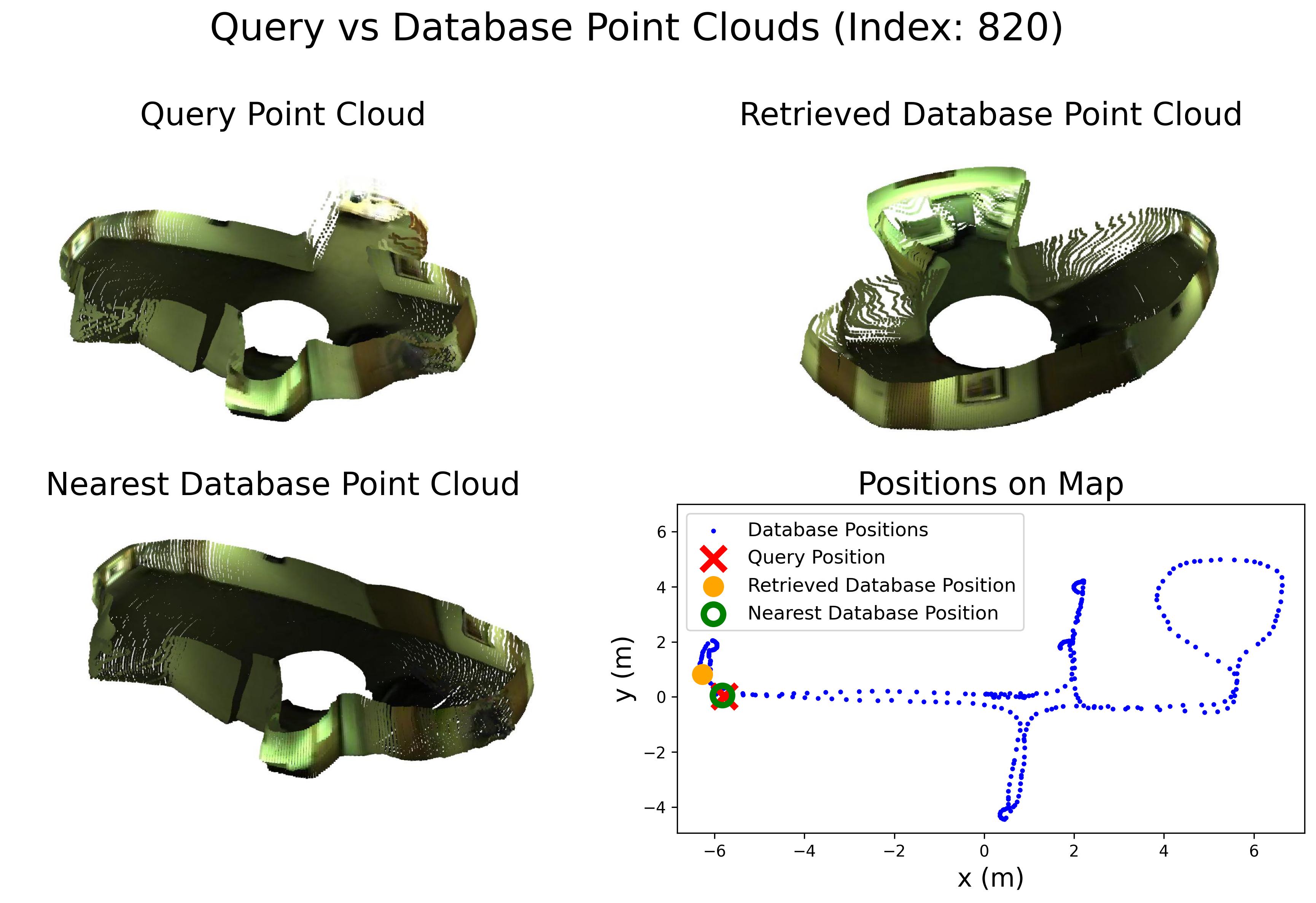
Comparison with other methods
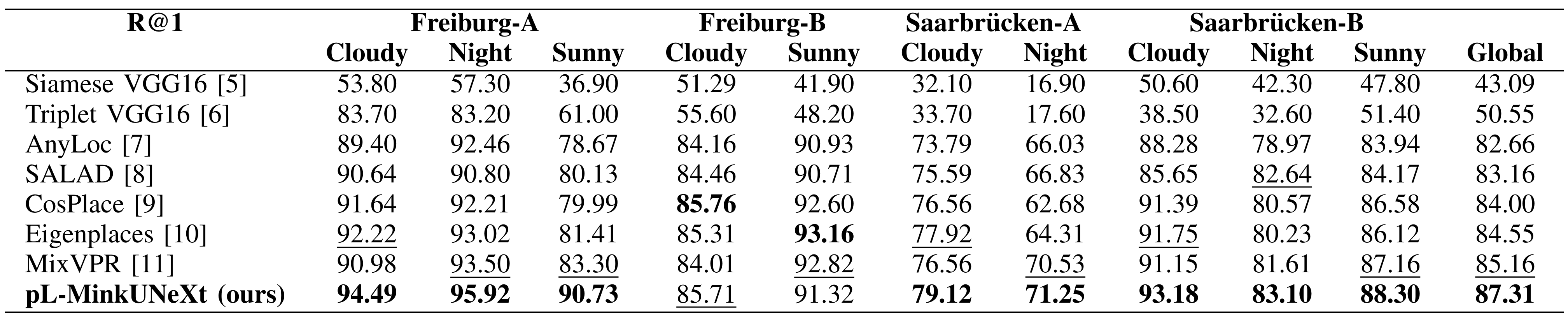
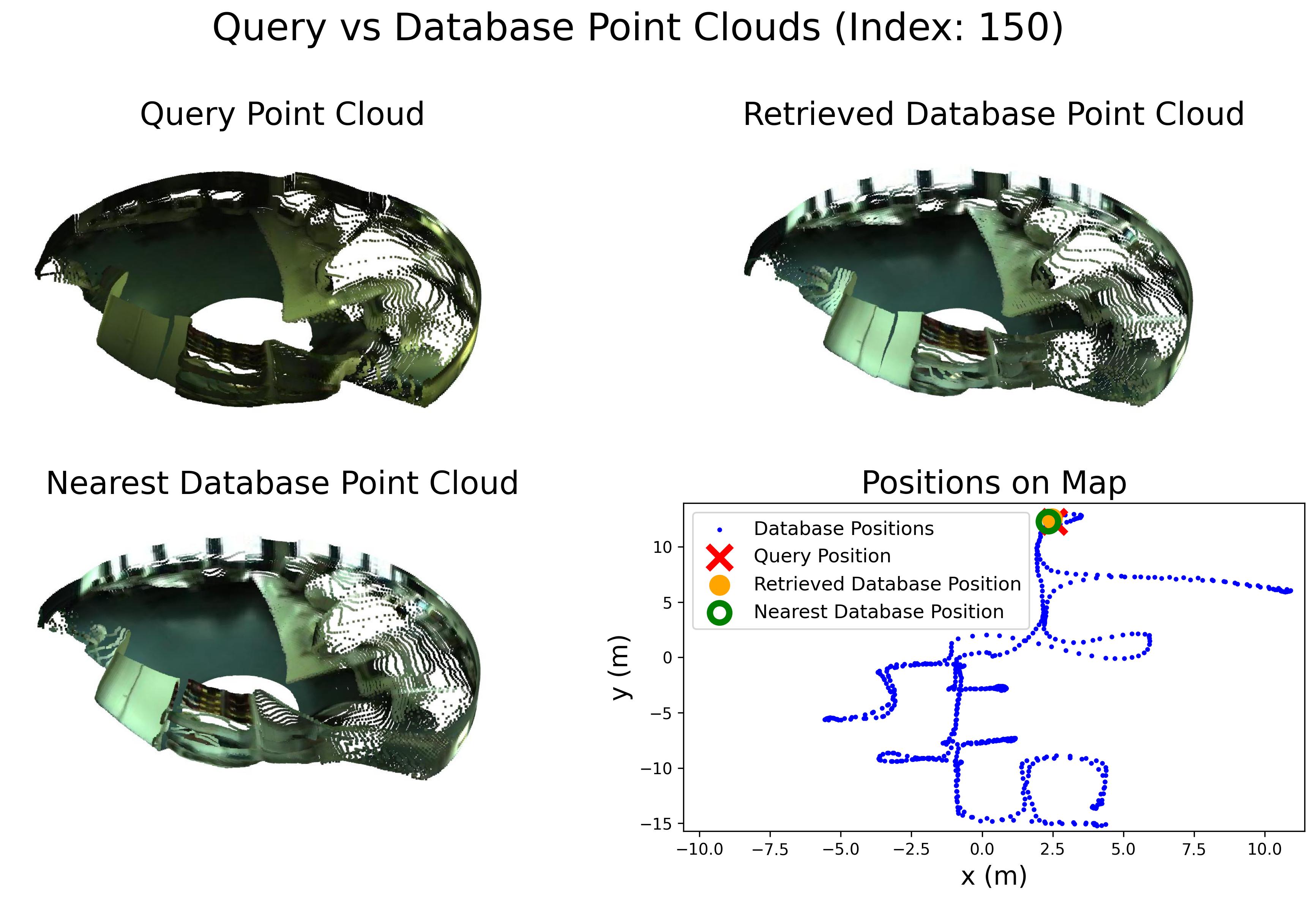
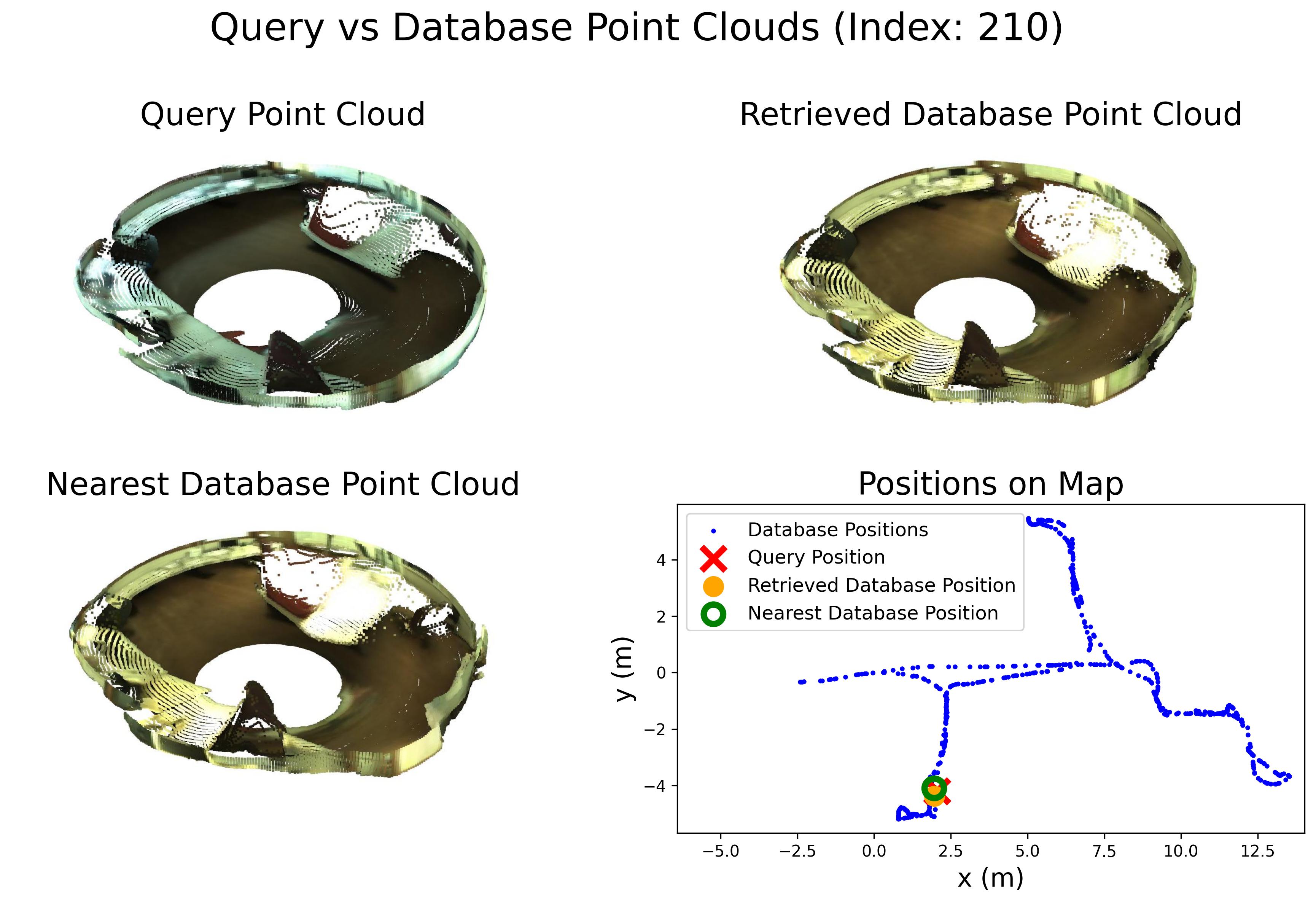
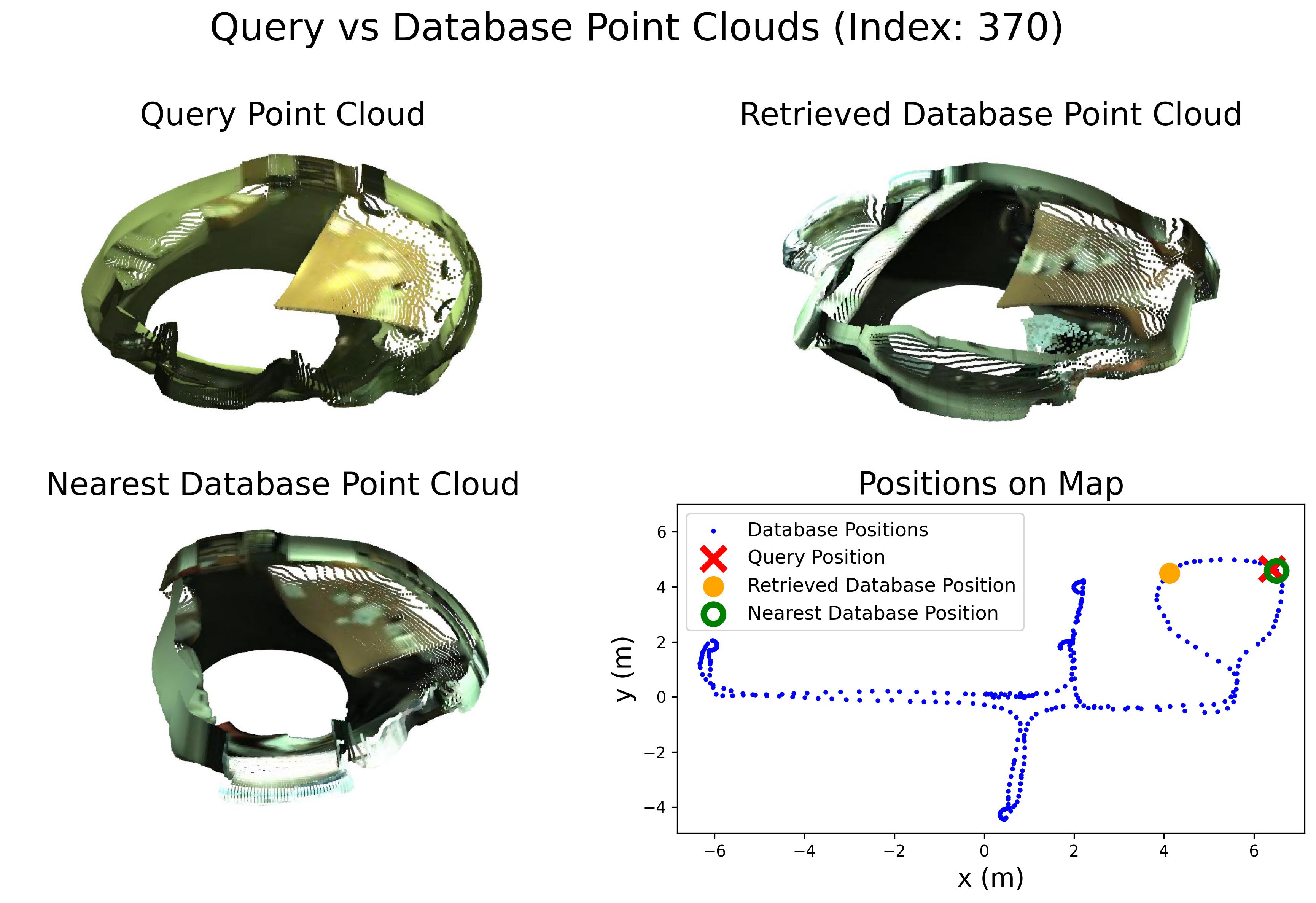
Comparison in terms of Recall@1 (R@1) with state-of-the-art methods.
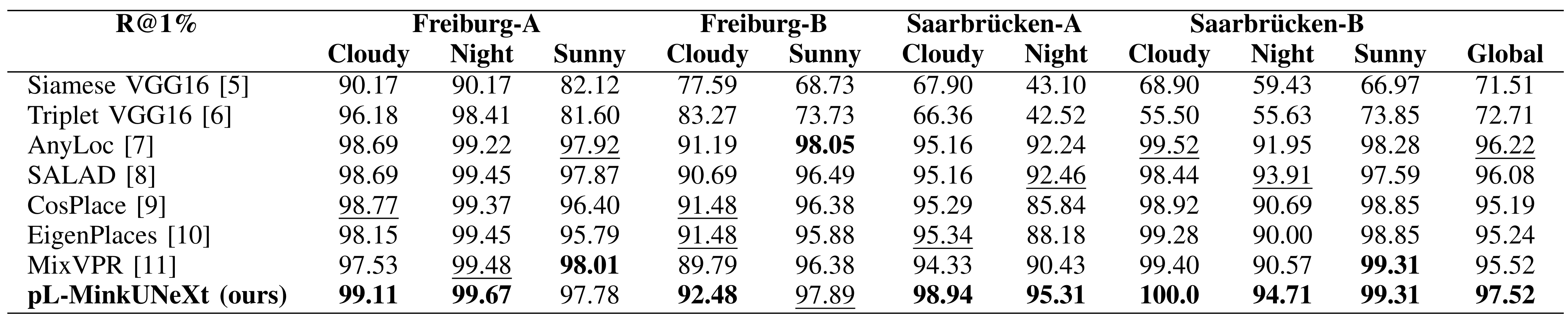
Comparison in terms of Recall@1% (R@1%) with state-of-the-art methods.
Bibliography:
[1] He, X., Guo, D., Li, H., Li, R., Cui, Y., Zhang, C.: Distill any depth: Distillation creates a stronger monocular depth estimator. arXiv preprint arXiv:2502.19204 (2025)
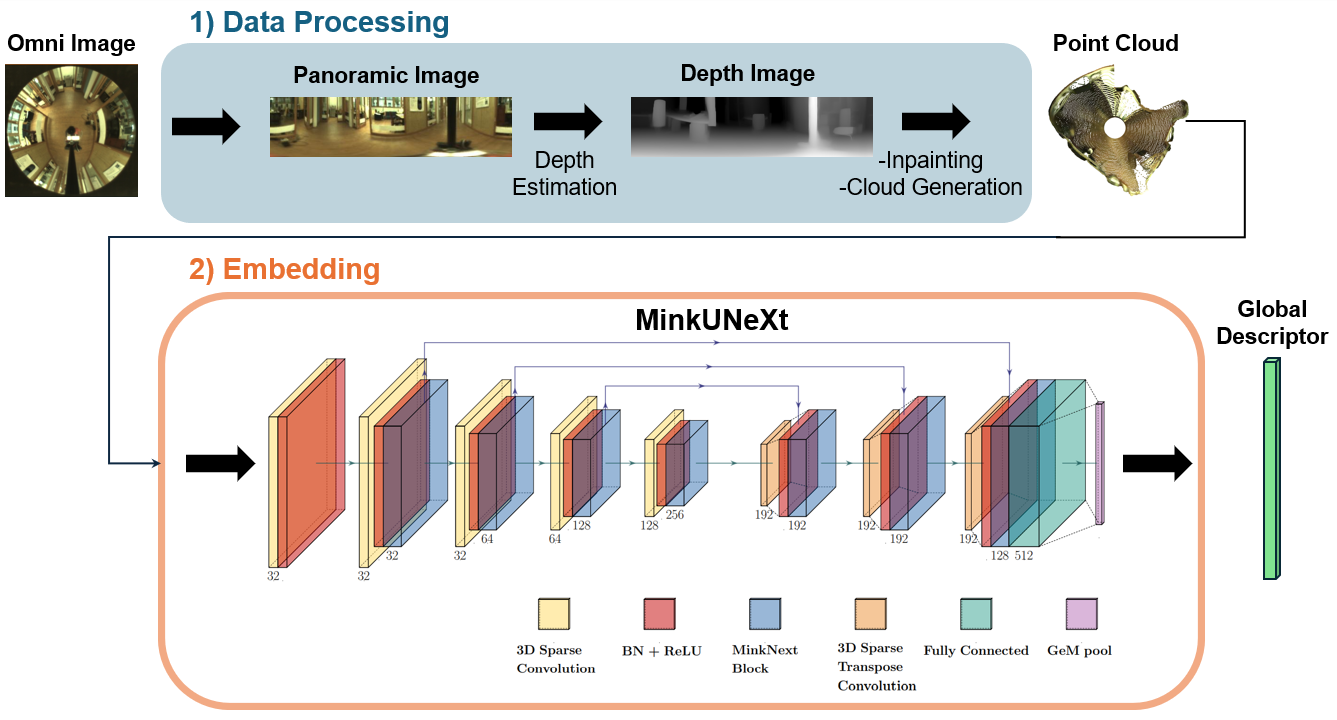
[2] Cabrera, J.J., Santo, A., Gil, A., Viegas, C., Payá, L.: MinkUNeXt: Point cloud-based large-scale place recognition using 3D sparse convolutions. arXiv preprint arXiv:2403.07593 (2024) https://doi.org/10.48550/arXiv.2403.07593
[3] Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth Anything v2. Advances in Neural Information Processing Systems 37, 21875-21911 (2025). https://doi.org/10.48550/arXiv.2406.09414
[4] Pronobis, A., Caputo, B.: COLD: the COsy Localization Database. The International Journal of Robotics Research 28(5), 588-594 (2009) https://doi.org/10.1177/0278364909103912
[5] Cabrera, J.J., Román, V., Gil, A., Reinoso, O., Payá, L.: An experimental evaluation of siamese neural networks for robot localization using omnidirectional imaging in indoor environments. Artificial Intelligence Review 57(198) (2024) https://doi.org/10.1007/s10462-024-10840-0
[6] Alfaro, M., Cabrera, J.J., Jiménez, L.M., Reinoso, O., Payá, L.: Triplet Neural Networks for the Visual Localization of Mobile Robots. In: Proceedings of the 21st International Conference on Informatics in Control, Automation and Robotics (ICINCO 2024), vol. 2, pp. 125-132 (2024). https://doi.org/10.5220/0012927400003822
[7] Izquierdo, S., Civera, J.: Optimal transport aggregation for visual place recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 17658-17668 (2024). https://doi.org/10.48550/arXiv.2311.15937
[8] Keetha, N., Mishra, A., Karhade, J., Jatavallabhula, K.M., Scherer, S., Krishna, M., Garg, S.: AnyLoc: towards universal visual place recognition. IEEE Robotics and Automation Letters (2023) https://doi.org/10.1109/LRA.2023.3343602
[9] Berton, G., Masone, C., Caputo, B.: Rethinking visual geo-localization for large-scale applications. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4878-4888 (2022). https://doi.org/10.48550/arXiv.2204.02287
[10] Berton, G., Trivigno, G., Caputo, B., Masone, C.: Eigenplaces: Training viewpoint robust models for visual place recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 11080-11090 (2023). https://doi.org/10.48550/arXiv.2308.10832
[11] Ali-Bey, A., Chaib-Draa, B., Giguere, P.: MixVPR: Feature mixing for visual place recognition. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 2998-3007 (2023). https://doi.org/10.48550/arXiv.2303.02190